Temporal Calibrating and Distilling for Scene-Text Aware Text-Video Retrieval
[1/9] Task Introduction
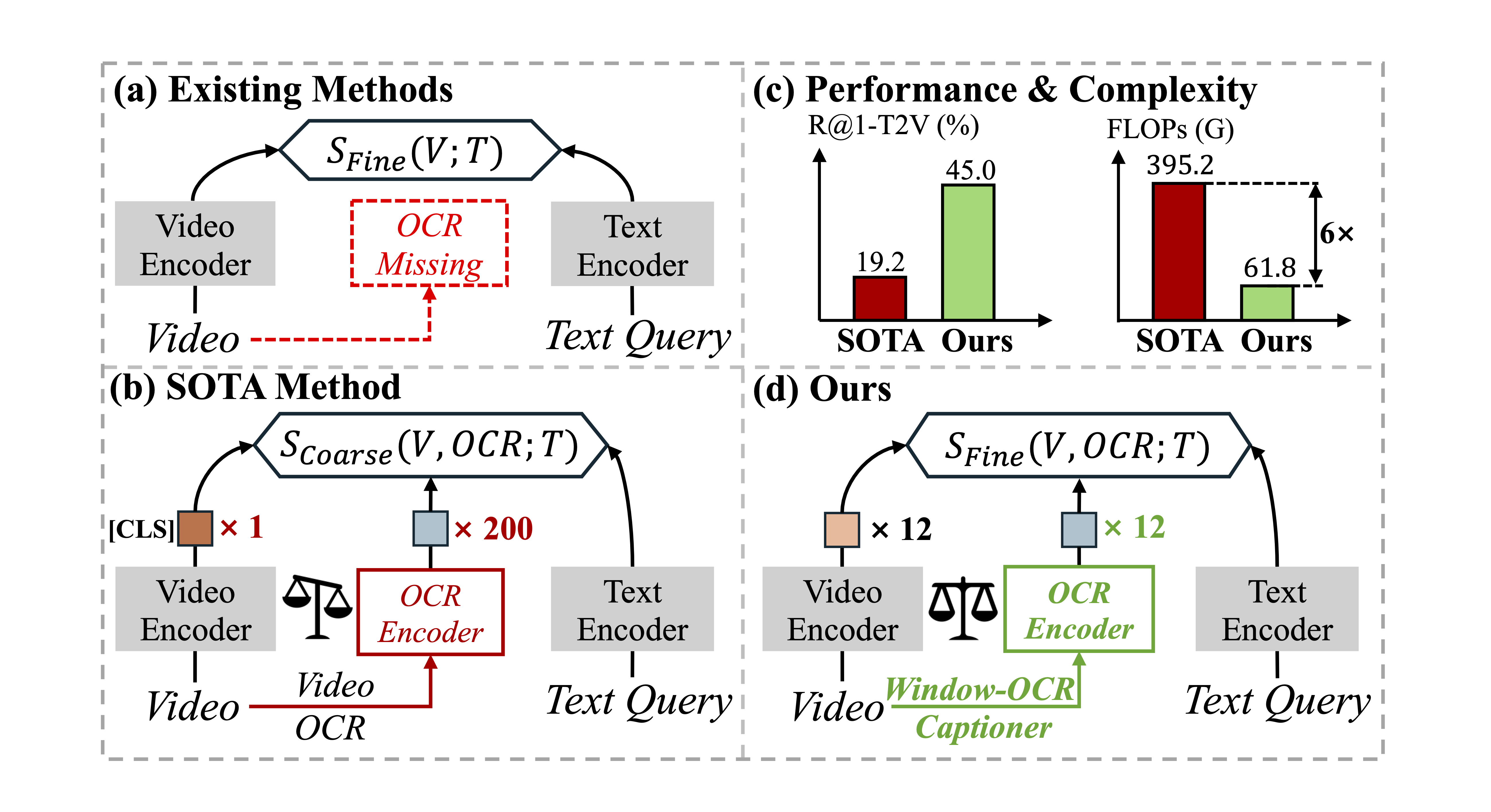
Figure 1: (a) Existing methods overlook fine-grained scene text in videos. (b) SOTA method treats scene text as isolated instances, resulting in token imbalance issue that limits fine-grained interactions. (d) Our window-OCR captioner condenses scene text into OCR captions, achieving better performance with lower complexity (c).
Examples in the TextVR Dataset
[2/9] Model Architecture
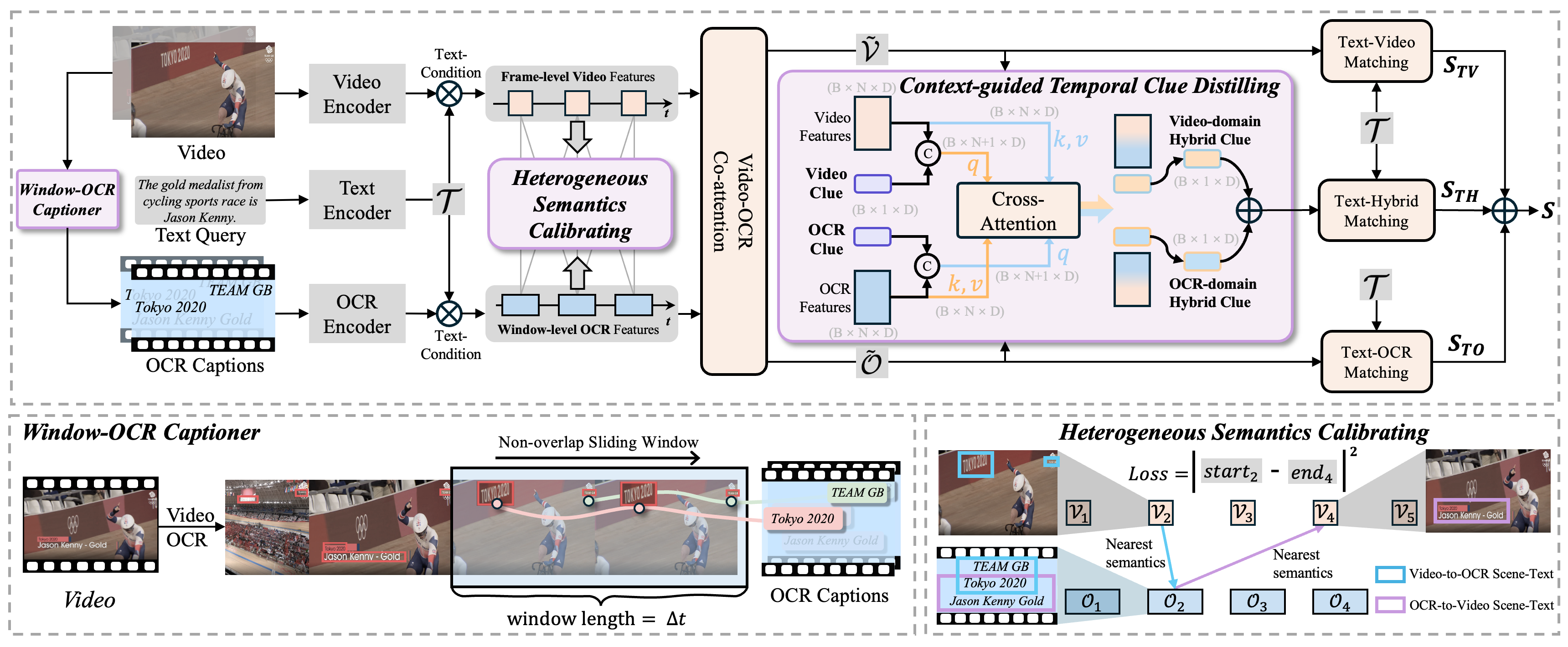
Figure 2: Pipeline of TCD. Window-OCR captioner condenses abundant scene text into OCR captions. Heterogeneous semantics calibrating leverages scene text present in both video and OCR captions as a self-supervised signal for temporal alignment. Context-guided temporal clue distilling assigns each modality a learnable clue token to extract clear temporal clues.
[3/9] Window-OCR Captioner 🌟🌟🌟

Figure 3: Visualization of the proposed Window-OCR Captioner. We aggregrate different kinds of scene texts appearing within a window length of ∆t into a single caption to reduce the feature length from N in previous works (e.g., StarVR) to 1.
[4/9] Visualization of Our Window-level Sampling Strategy
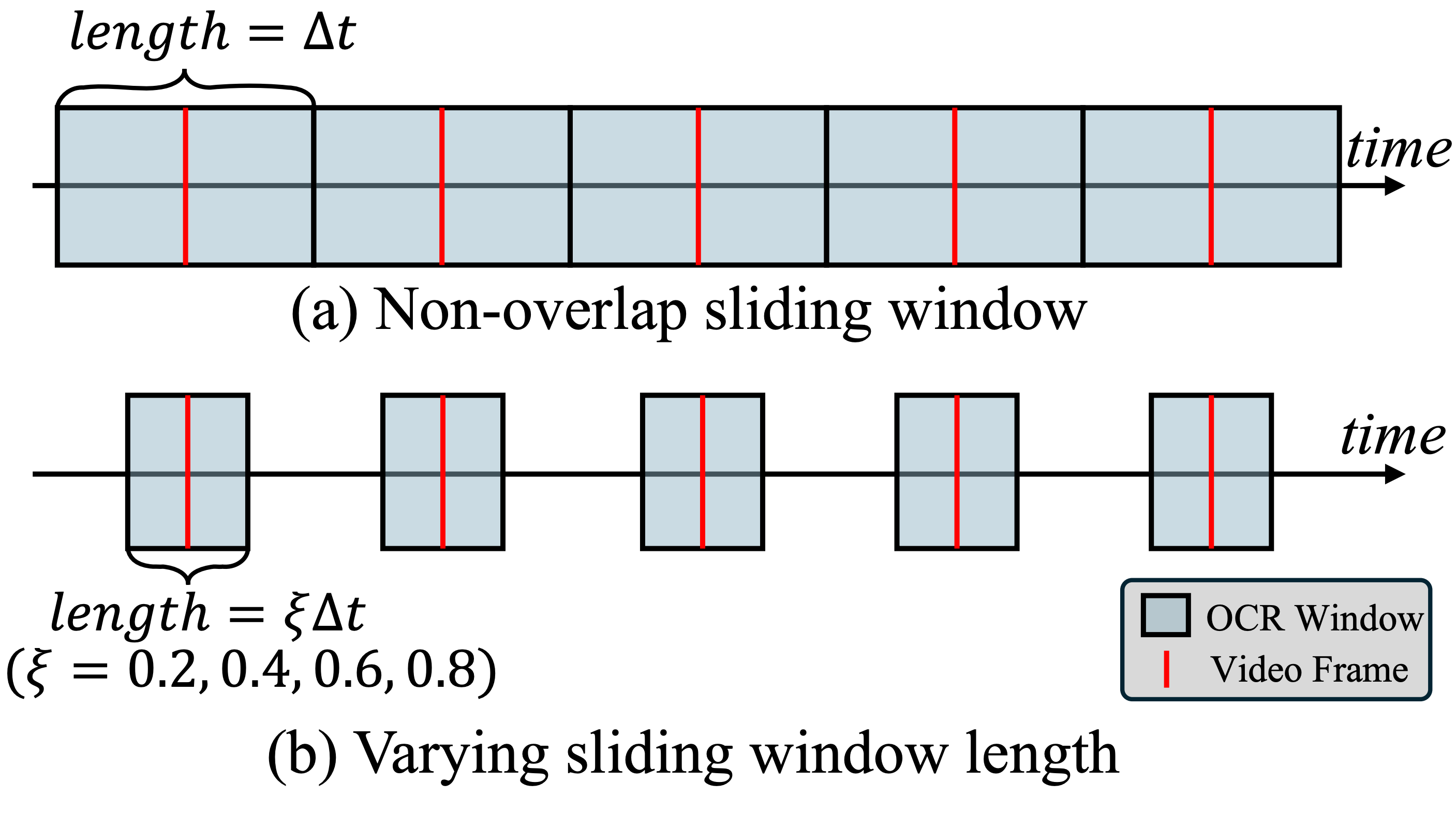
Figure 4: Our window-level sampling strategy samples scene text using non-overlapping sliding windows. We sample scene text with a window centered around each video frame. Here, a larger window length value corresponds to sampling more scene text.
[5/9] Heterogeneous Semantics Calibrating
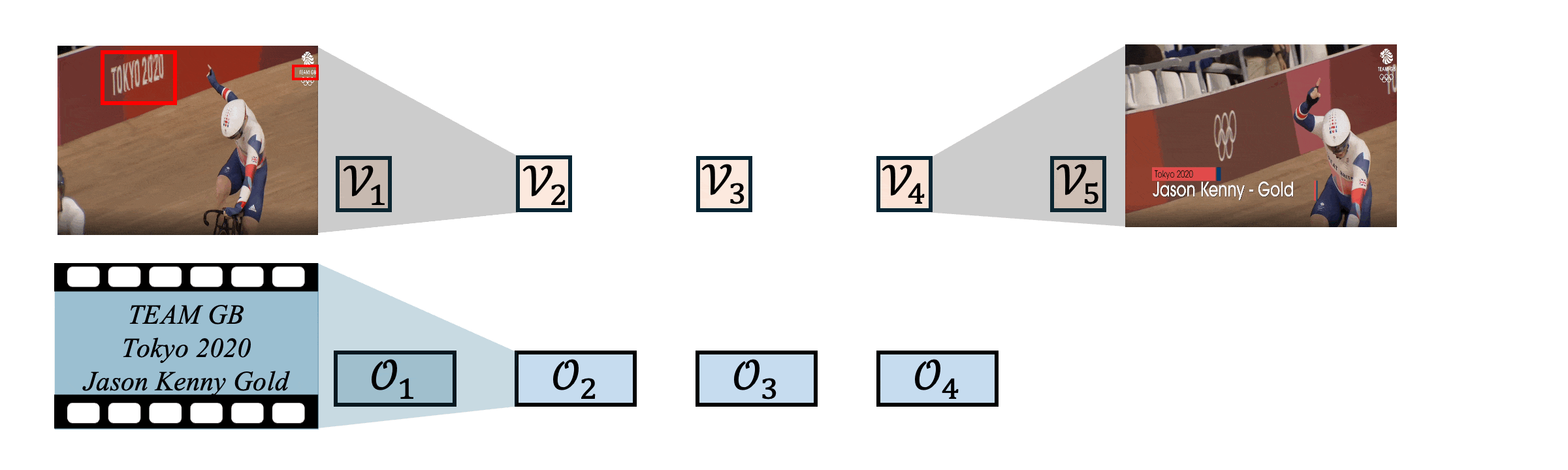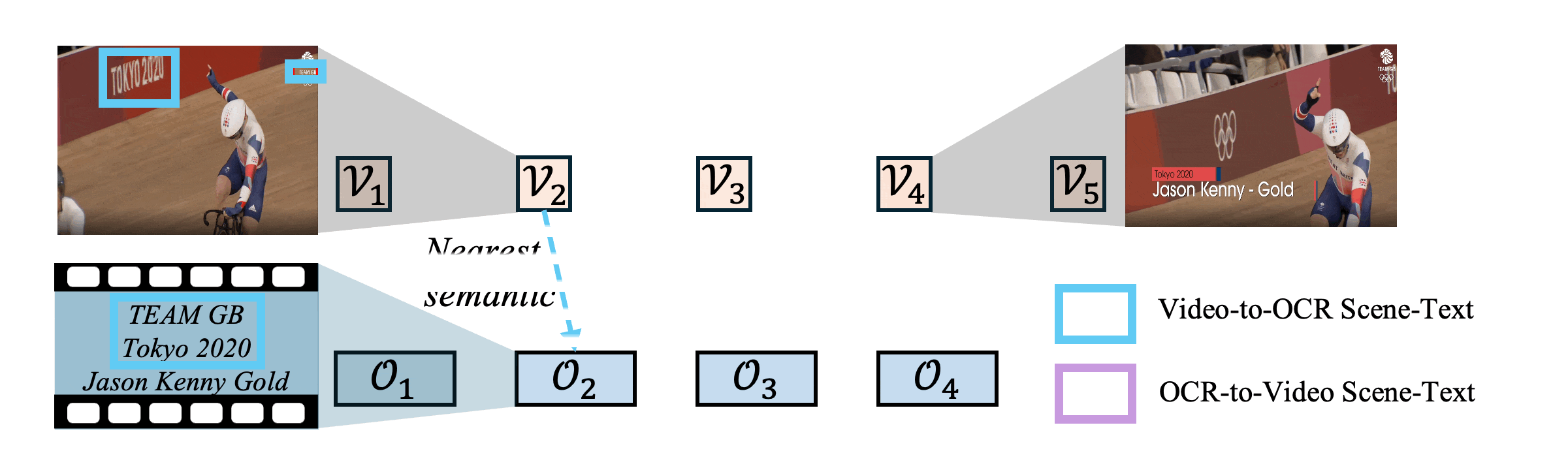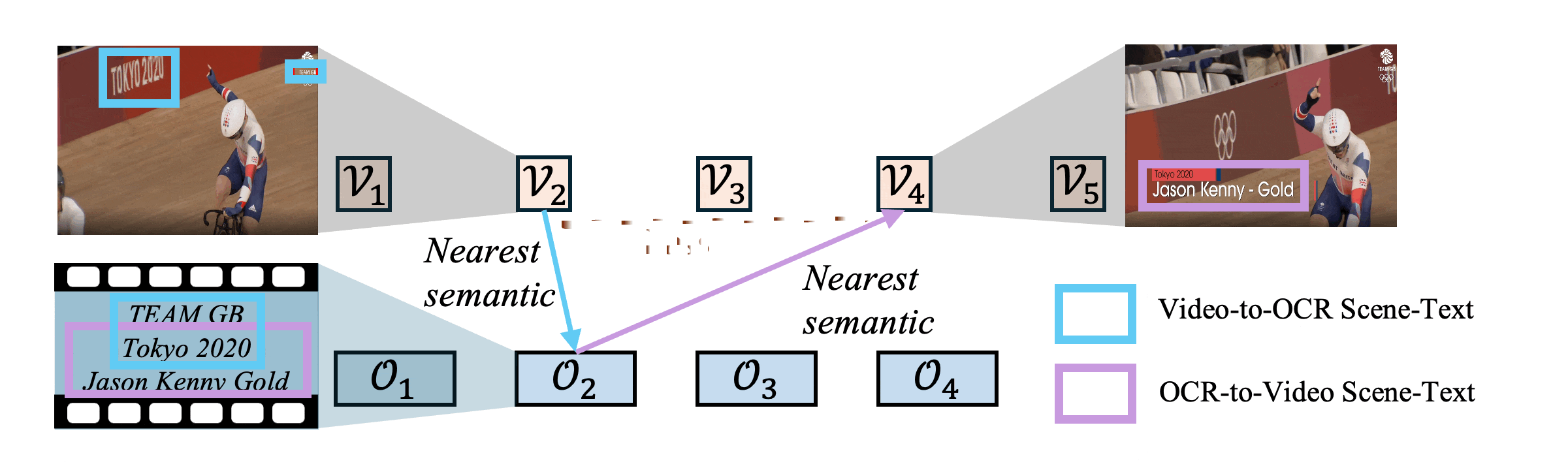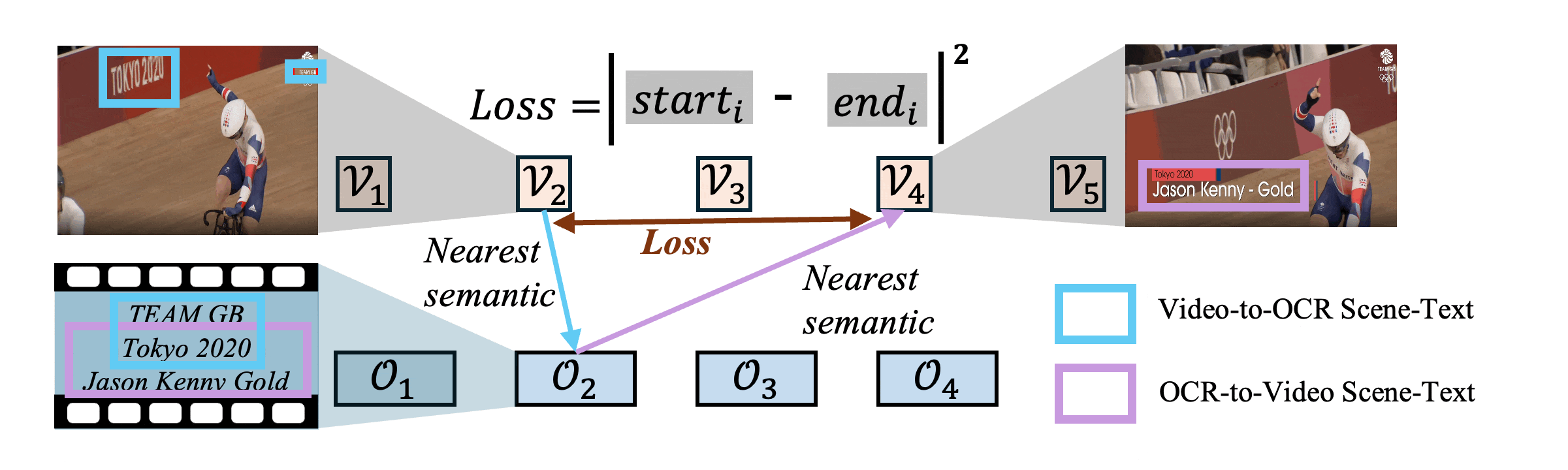
Figure 5: Demo of the proposed Heterogeneous Semantics Calibrating. We leverage heterogeneous scene text as the calibration signal to align sequences with different time-scales. The nearest semantic match follows the highest similarity score between the element in the first sequence and each element in the second sequence.
[6/9] Text→Video Retrieval Results (1/2)

Figure 6: Visualization of retrieval results comparing our method (left) with the model without OCR information (right). Sim indicates the overall similarity score, calculated as the average of text-OCR, text-video, and text-hybrid matching scores, denoted as OCR, Video, and Hybrid, respectively. Our TCD captures fine-grained scene text, such as "GRILL" and "Thank you" with high similarity and hybrid scores. Please zoom in for a better view of the details.
[7/9] Text→Video Retrieval Results (2/2)

Figure 7: Visualization of retrieval results comparing our method (left) with the model without OCR information (right). Sim represents the overall similarity score, calculated as the average of text-OCR, text-video, and text-hybrid matching scores, denoted as OCR, Video, and Hybrid, respectively. Our TCD captures fine-grained scene text, such as "SAC MIA", "School", and "SDY 288H" with high similarity and hybrid scores. Please zoom in for a better view of the details.
[8/9] Appendix

[9/9] Abstract
The source code and trained models will be released soon.